Procédure de sauvegarde informatique : modèle + calculateur RTO/RPO
Cet article traite de sauvegarde informatique (backup des données d’entreprise).
⚖️ À ne pas confondre avec la procédure de sauvegarde au sens juridique (procédure collective).

🧭 Procédure de sauvegarde
Pourquoi documenter une procédure de sauvegarde (et ce que vous allez obtenir)
La procédure de sauvegarde est la pierre angulaire de votre résilience IT : elle formalise qui fait quoi, quand et comment pour protéger, vérifier et restaurer vos données critiques. Sans ce référentiel opérationnel, vos objectifs RTO (Recovery Time Objective) et RPO (Recovery Point Objective) restent théoriques ; le jour d’un incident ou d’un ransomware, l’improvisation coûte du temps, des données et de l’argent. À ne pas confondre avec la procédure de sauvegarde au sens juridique (procédure collective), ce guide s’adresse aux équipes IT/SECOPS qui pilotent la sauvegarde d’entreprise sur des environnements on-prem, sauvegarde cloud ou hybrides (VM, bases, Microsoft 365, Kubernetes, fichiers). Vous y trouverez des bonnes pratiques éprouvées (règle 3-2-1, sauvegarde immuable, chiffrement des données) et un mode opératoire orienté PRA/DRP pour tenir vos engagements de service.
Dans ce guide, vous accédez à :
- Un modèle prêt à l’emploi de procédure de sauvegarde (Word) pour cadrer rôles, périmètres, politiques et tests.
- Un calculateur RTO/RPO (Excel/Sheets) pour dimensionner vos fenêtres de restauration et valider la capacité réelle.
Objectif : passer d’intentions à une exécution mesurée, auditable et optimisée en coûts (déduplication, tiering, archivage).
🗂️ Gouvernance
Rôles, responsabilités et périmètres
Une procédure de sauvegarde efficace s’appuie sur une gouvernance claire : qui décide, qui exécute, qui contrôle. Installez un RACI pour votre sauvegarde d’entreprise ; séparez les tâches (PAM), sécurisez les accès (MFA, RBAC), formalisez la validation SecOps sur le chiffrement des données, l’immutabilité (WORM), l’air-gap et la conformité (RGPD). Les Owners métiers définissent la criticité (P0→P3) et les objectifs RTO/RPO ; le Backup Admin automatise, supervise et prouve la restauration ; le Sponsor arbitre budgets et priorités PRA/DRP.
Cartographiez le périmètre :
- Environnements : on-prem, sauvegarde cloud, hybride/multicloud, sites distants.
- Workloads : VM/hyperviseur, bases (SQL/NoSQL), fichiers/NAS, Microsoft 365/OneDrive (Exchange, SharePoint, Teams), Kubernetes (volumes CSI), SaaS critiques, endpoints.
- Contraintes : fenêtres de sauvegarde, volumétrie/jour, dépendances applicatives, débits de restauration, rétentions légales.
- Sécurité : immutabilité (durées), air-gap, chiffrement, gestion de clés (KMS/HSM), comptes dédiés.
KPI à suivre :
- Taux de succès des jobs ; respect RPO/RTO ; couverture sauvegarde immuable ; ratios déduplication/compression ; MTTR de restauration ; détection d’anomalies/ransomware.
| Rôle | Responsabilités clés |
|---|---|
| ✨ Sponsor (DSI/DGD) | Valide la politique, arbitre les budgets, tranche en cas de conflit de priorités. |
| 🛠️ Backup Admin | Opère la plateforme, automatise, surveille, exécute les tests de restauration. |
| 🔐 SecOps/RSSI | Valide chiffrement des données, accès, durées d’immutabilité, segmentation/air-gap. |
| 💼 Owner Métier | Classe les applications (P0→P3), choisit RTO/RPO, approuve les plans de reprise. |
| 📣 Comms/Support | Communication de crise, gestion d’incident, coordination PRA/DRP. |
📊 Classification & criticité
ce qui guide RTO/RPO
La classification des données conditionne vos objectifs RTO/RPO et vos politiques de sauvegarde d’entreprise. Sans priorisation, tout devient “critique”, les coûts (stockage, egress, archivage) explosent et la reprise d’activité se grippe. L’objectif est d’aligner la criticité métier avec des politiques mesurables (fréquences, rétentions, sauvegarde immuable, 3-2-1, chiffrement des données) et des capacités réalistes de restauration de données.
Méthode (concrète) :
- Inventorier applications et jeux de données : VM/DB, fichiers/NAS, Microsoft 365/OneDrive, Kubernetes, SaaS.
- Évaluer l’impact (BIA) : revenus, conformité (RGPD), réputation, dépendances (AD/IAM, DNS, réseau, stockage).
- Mesurer la réalité technique : fenêtres de sauvegarde, volumétrie/jour, débits de restauration atteignables on-prem/cloud.
- Arbitrer avec les Owners : signature de la matrice de criticité (P0→P3) et des objectifs RTO/RPO.
Échelle de criticité (à intégrer dans la procédure) :
| 🏷️ Niveau | Exemples | RPO recommandé | RTO recommandé |
|---|---|---|---|
| 🧪 P0 – Vital | ERP Finance, E-commerce, SIRH paie | ≤ 15 min | ≤ 4 h |
| ⚠️ P1 – Critique | CRM, MES, SharePoint prod | ≤ 1 h | ≤ 8 h |
| ⏳ P2 – Important | BI non temps réel, intranet | ≤ 4 h | ≤ 24 h |
| 🗂️ P3 – Standard | Archives, lab | ≤ 24 h | ≤ 72 h |
Livrables attendus :
- Matrice P0→P3 signée, politiques de sauvegarde associées (fréquences, rétentions, immutabilité WORM, air-gap).
- Runbooks de restauration par classe + preuves de tests (PRA/DRP).
- Revue trimestrielle : dérives de RPO, respect des RTO, optimisation TCO (déduplication, tiering, archivage).
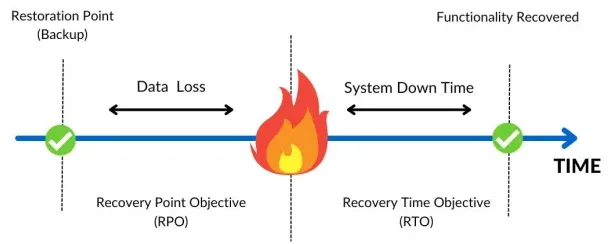
⏱️ Fixer des RTO/RPO réalistes (et mesurables)
Des RTO/RPO crédibles partent de la réalité terrain, pas d’un vœu pieux. L’objectif est de traduire l’impact métier en capacités de sauvegarde/restauration atteignables sur vos infrastructures on-prem, sauvegarde cloud ou hybrides.
Entrées nécessaires :
- Volumétrie par application (plein + incrémental), croissance mensuelle (%).
- Fenêtres de sauvegarde, débits de restauration mesurés, concurrence des jobs.
- Criticité P0→P3, contraintes légales (RGPD, rétention), exigences PRA/DRP.
Méthode en 5 étapes :
- Mesurez la performance réelle (backup et restauration) sur un échantillon représentatif.
- Calculez le “worst day” : To à restaurer en parallèle pour revenir au RPO exigé.
- Dimensionnez les voies de données : nombre de flux, cible de stockage, network, tiering local/cloud.
- Sécurisez la base : sauvegarde 3-2-1, sauvegarde immuable (WORM), chiffrement des données, air-gap pour éviter la remise à zéro post-incident.
- Validez par des tests de restauration (mensuels/trimestriels) et alignez les SLO métiers.
Règles pratiques :
- P0 : RPO ≤ 15 min → journalisation/CDC, snapshots fréquents, réplication courte distance.
- RTO court : privilégiez cibles locales performantes (recovery “nearline”) + rétention économique en cloud.
- Rapports : suivez respect RPO/RTO, dérives de volumétrie, MTTR, anomalies (anti-ransomware).
🧮 Le calculateur RTO/RPO fourni projette volumes & débits, détecte les goulets (réseau/stockage) et propose des scénarios d’arbitrage coût/risque.
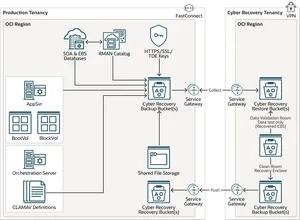
🛡️ Architecture de sauvegarde
3-2-1, sauvegarde immuable, air-gap
La règle 3-2-1 reste la base de toute procédure de sauvegarde robuste : 3 copies des données, 2 médias différents, 1 copie hors site. Pour résister aux ransomwares, complétez-la avec une sauvegarde immuable et un air-gap (isolation logique ou physique).
Principes essentiels :
- Immutabilité (WORM/Object Lock) : empêche la suppression/modification pendant N jours ; socle d’une restauration saine.
- Air-gap : séparation réseau/comptes (coffre-fort logique, vault dédié, bande hors ligne).
- Zero Trust : RBAC, MFA, comptes d’administration séparés, journaux inviolables.
- Chiffrement des données : en transit (TLS) et au repos (AES-256) avec KMS/HSM et rotation de clés.
Patrons d’architecture (à adapter) :
- On-prem : primaire (NAS/Bloc) → réplique immutable (stockage objet) → copie hors site (bande/objet).
- Hybride : primaire local “nearline” pour RTO courts → tiering vers objet immutable (cloud) + archiving.
- Cloud-first : sauvegarde directe vers stockage objet multi-région avec politiques WORM et clés managées.
Contrôles à documenter :
- Durée d’immutabilité par classe (P0→P3).
- Fréquence de vérification des verrous (Object Lock, retention mode).
- Tests de restauration depuis le coffre immuable (preuve ≤ 90 jours).
- Scénario “site perdu” : parcours de reprise validé (PRA/DRP), temps de montée en charge, coûts d’egress.
👉 Objectif : combiner résilience (immutabilité + air-gap) et performance de recovery (cible rapide), tout en contenant le TCO grâce au tiering et à l’archivage long terme.

☁️ Cloud vs sur site (ou hybride) : comment choisir
Le bon modèle dépend de vos objectifs RTO/RPO, de la sécurité, des coûts (TCO) et des contraintes RGPD. L’idée n’est pas “cloud ou on-prem”, mais de trouver la combinaison qui maximise la restauration tout en maîtrisant le budget.
Critères de décision :
- Sécurité & contrôle : gestion des clés (KMS/HSM), immutabilité (WORM/Object Lock), air-gap, Zero Trust.
- Performance & latence : restauration “nearline” locale pour P0/P1 ; bande passante, fenêtres de sauvegarde cloud.
- Coûts (TCO) : stockage primaire vs stockage objet (S3-like), frais d’egress cloud, tiering et archivage long terme.
- Conformité & souveraineté des données : zones, localisation, RGPD, durées de rétention.
- Opérations : automatismes, supervision, compétences internes, sites distants/ROBO.
Quand privilégier…
- Sur site (on-prem) : RTO très courts, dépendances locales, volumétrie élevée ; cible de restauration performante.
- Cloud : élasticité, classes économiques, immutabilité managée, sauvegarde cloud entreprise multi-région.
- Hybride : le plus courant — recovery rapide local + solution sauvegarde cloud pour rétention économique et PRA/DRP.
Bonnes pratiques :
- Modèle 3-2-1 : cible locale + réplique immutable + copie hors site.
- Tiering automatique : chaud → tiède → froid/archivage (optimise le TCO).
- Sorties testées : preuves de restauration depuis le coffre immuable ≤ 90 j.
- Suivi coûts : tableaux de bord egress, croissance, ratios déduplication/compression.
👉 Résultat : un design hybride bien pensé combine résilience, coût maîtrisé et conformité.
🧩 Politiques opérationnelles
Fréquences, rétentions, chiffrement
Des politiques de sauvegarde claires transforment vos objectifs RTO/RPO en exécution quotidienne. Elles couvrent fréquences, fenêtres, rétentions, chiffrement des données et contrôles de sauvegarde immuable. Documentez-les dans la procédure de sauvegarde et reliez chaque règle à un niveau de criticité (P0→P3).
Fréquences recommandées :
- P0 : incrémental 15–30 min + complet synthétique hebdo (journalisation/CDC quand possible).
- P1 : incrémental horaire + complet hebdo.
- P2/P3 : incrémental quotidien + complet bi-hebdo/mensuel.
- SaaS/Microsoft 365 : cadence adaptée aux SLA métier (Exchange/SharePoint/OneDrive/Teams).
- Kubernetes : snapshots CSI coordonnés avec la cohérence applicative (DB, queues, secrets).
Rétentions & conformité :
- Court terme : 7–30 jours pour la restauration rapide.
- Moyen terme : 3–6 mois pour erreurs latentes.
- Long terme/Archivage : 1–7 ans selon RGPD/légal.
- Activez WORM/Object Lock (durées par P0→P3) et prévoyez l’air gap.
Fenêtres & performance :
- Définissez les fenêtres de sauvegarde hors pics ; évitez les chevauchements ; surveillez débit et déduplication/compression.
- Pour RTO courts, cible “nearline” locale + tiering vers stockage objet pour le TCO.
Sécurité & clés :
- Chiffrement en transit (TLS) et au repos (AES-256).
- Gestion des clés (KMS/HSM), rotation, séparation des rôles, procédure de recovery des clés.
- Audit : rapports de conformité, preuve d’immutabilité, alertes d’échec.
🔁 Tester, auditer, améliorer : l’assurance qualité des restaurations

Les tests de restauration transforment votre procédure de sauvegarde en garanties concrètes : sans preuves, vos RTO/RPO restent théoriques. Planifiez, exécutez, mesurez et auditez—c’est la base d’une résilience IT face au ransomware.
Planifier les tests :
- Mensuel : échantillon aléatoire (fichiers, VM, base) pour valider la restauration “nearline”.
- Trimestriel (tabletop PRA/DRP) : scénario bout-en-bout avec métiers, SecOps, Backup Admin et communication de crise.
- Annuel : test “site perdu” (région/Datacenter), vérification air-gap et sauvegarde immuable (WORM/Object Lock).
Scénarios à couvrir :
- Corruption logique / suppression accidentelle (RPO serré).
- Chiffrement par ransomware (reprise depuis coffre immutable).
- Panne stockage / réseau / annuaire (AD/IAM).
- Défaillance applicative distribuée (micro-services, Kubernetes).
Preuves & audit :
- Captures, journaux, hash d’intégrité, horodatages, responsabilité (RACI).
- Feuille de route corrective (capacités, politiques, chiffrement des données, formation).
KPI à suivre :
| KPI | Cible | |
|---|---|---|
| 📈 | Taux de réussite de restauration | ≥ 98 % |
| 🕒 | Respect RTO (P0) | ≥ 95 % des cas |
| ⏳ | Respect RPO (P0) | ≥ 99 % des jobs |
| 🔒 | Couverture immutabilité | 100 % P0/P1 |
Bonnes pratiques :
- Automatiser les tests (sandbox), isoler les réseaux, documenter les temps.
- Simuler l’indisponibilité de clés (KMS/HSM) et la rotation d’accès (Zero Trust).
- Inclure coûts d’egress dans le plan de restauration cloud.
📈 Observabilité & détection : passer du réactif au proactif
L’observabilité transforme votre procédure de sauvegarde en pilotage quotidien. Elle combine monitoring sauvegarde, détection d’anomalies et alerting pour garantir le respect des RTO/RPO et la résilience face au ransomware. L’objectif : voir tôt, réagir vite, prouver la conformité.
Ce qu’il faut mesurer :
- Santé des jobs : taux de succès/échecs, durée, files d’attente, fenêtres dépassées.
- Qualité des données : ratios déduplication/compression, dérives de volumétrie, taux de changements inhabituel.
- Capacité & performance : IOPS/throughput de restauration, saturation réseau/stockage, coûts egress en sauvegarde cloud.
- Sécurité : couverture sauvegarde immuable (WORM), échecs MFA/RBAC, accès privilégiés, tamper detection.
Alertes et détection avancée :
- Anomaly detection (heuristiques/ML) : pic d’incrémentaux, baisse soudaine de dédup, explosion des fichiers chiffrés—signaux de ransomware.
- RTO/RPO at risk : alerte prédictive quand les restaurations “worst day” ne passent plus.
- Intégrations : export vers SIEM/SOC (Syslog, API), playbooks SOAR pour enclencher gel des comptes, isolation réseau, bascule PRA/DRP.
Tableaux de bord & gouvernance :
- Vue exécutive (DSI) : conformité RTO/RPO, disponibilité des coffres immutables.
- Vue opérations : jobs, files, capacité, tickets.
- Revues mensuelles : écarts, MTTR, optimisation tiering/stockage objet, plan d’action.
👉 Résultat : une posture proactive qui sécurise les RTO/RPO, réduit les MTTR et prévient les incidents coûteux.
💶 Maîtriser le TCO
Dédup, compression, tiering & archivage
Le coût total de possession (TCO) d’une sauvegarde d’entreprise dépend surtout de la rétention et des restaurations, plus que du premier full. L’objectif : tenir RTO/RPO tout en optimisant stockage et egress en cloud ou hybride.
Ce qui fait varier le TCO :
- Volumétrie (pleins/incrémentaux), croissance mensuelle, fenêtres et SLA de restauration.
- Durées de rétention (court/moyen/long terme), exigences RGPD/audit.
- Classes de stockage : local “nearline”, stockage objet (S3-like), archivage long terme.
Leviers concrets :
- Déduplication & compression : maximiser les ratios (suivi par job) ; revoir les blocs/salts.
- Tiering automatique : chaud → tiède → froid (objet) ; au-delà de X jours, basculer en Glacier/Archive.
- Immutabilité (Object Lock/WORM) : calibrer la durée par P0→P3 pour éviter une rétention trop longue.
- Egress : privilégier recovery local (staging) ; éviter restore massif depuis le cloud pour P2/P3.
- Planification : réduire chevauchements, lisser pics réseau/IO ; consolidation “synthetic full”.
- Lifecycle : politiques expirant copies secondaires ; air-gap activé uniquement sur jeux critiques.
Indicateurs à suivre :
- Ratio dédup/compression, coût €/To/mois par classe, % données en archive, coûts egress, MTTR vs RTO.
Pièges fréquents :
- Conserver des données froides en classe chaude.
- Durées d’immutabilité trop longues par défaut.
- Absence de scénarios “worst day” dans le budget de restauration cloud.
📥 Téléchargement : Modèle de procédure + Calculateur RTO/RPO
Ce que vous téléchargez :
- Modèle Word : politique, RACI, inventaire, politiques, procédures de restauration par criticité, tests, audit.
- Calculateur Excel/Sheets : onglets Paramètres, RTO/RPO, Capacité, Planification, KPI, Budget/TCO.